¿Cuál es la diferencia entre la ciencia de datos y la inteligencia artificial?




¿Cuál es la diferencia entre la ciencia de datos y la inteligencia artificial?
Tanto la ciencia de datos como la inteligencia artificial (IA) son términos generales para los métodos y técnicas relacionados con la comprensión y el uso de datos digitales. Las organizaciones modernas recopilan información de una variedad de sistemas físicos y en línea sobre todos los aspectos de la vida humana. Disponemos de grandes cantidades de datos de texto, audio, video e imágenes. La ciencia de datos combina herramientas estadísticas, métodos y tecnología para generar significado a partir de los datos. La inteligencia artificial va un paso más allá y utiliza los datos para resolver problemas cognitivos comúnmente asociados con la inteligencia humana, como el aprendizaje, el reconocimiento de patrones y la expresión similar a la humana. Es una colección de algoritmos complejos que “aprenden” a medida que avanzan, mejorando en la resolución de problemas con el tiempo.
Similitudes entre la ciencia de datos y la inteligencia artificial
Tanto la inteligencia artificial como la ciencia de datos incluyen herramientas, técnicas y algoritmos para analizar y utilizar grandes volúmenes de datos. A continuación se presentan algunas similitudes.
Programas predictivos
Tanto la inteligencia artificial como las tecnologías de ciencia de datos hacen predicciones basadas en datos nuevos, como resultado de aplicar modelos y métodos aprendidos al analizar datos anteriores. Por ejemplo, predecir las futuras ventas mensuales de paraguas a partir de los datos de años anteriores es un ejemplo de análisis de datos de series temporales dentro de la ciencia de datos.
Del mismo modo, un automóvil autónomo es un ejemplo de sistema de inteligencia artificial predictiva. Cuando un automóvil autónomo está en la carretera, calcula la distancia al automóvil de adelante y la velocidad de ambos vehículos. Mantiene su velocidad a un ritmo que evitaría un choque, ya que se basa en la predicción del frenado repentino del automóvil de delante.
Requisitos de calidad de los datos
Tanto la IA como las tecnologías de ciencia de datos ofrecen resultados menos precisos si los datos de entrenamiento son inconsistentes, sesgados o incompletos. Por ejemplo, los algoritmos de ciencia de datos e inteligencia artificial pueden:
- filtrar los datos nuevos si es que son completamente nuevos y no están en su conjunto de datos original,
- priorizar los atributos específicos del conjunto de datos sobre todos los demás si los datos de entrada carecen de variación,
- crear información inexistente o ficticia porque los datos de entrada eran falsos.
Machine learning
Machine learning (ML) se considera un subtipo de la ciencia de datos y la inteligencia artificial. Esto significa que todos los modelos de ML se consideran modelos de ciencia de datos y todos los algoritmos de ML también se consideran algoritmos de IA. Existe la idea errónea de que toda la IA usa ML, pero este no es el caso. ML no siempre es necesario en las soluciones de IA complejas. Del mismo modo, no todas las soluciones de ciencia de datos incluyen ML.
Diferencias clave: ciencia de datos en comparación con inteligencia artificial
La ciencia de datos implica analizar los datos para determinar los patrones subyacentes y los puntos de interés para hacer predicciones. La ciencia de datos aplicada toma los modelos y métodos utilizados en el análisis de datos y los aplica a nuevos datos en situaciones del mundo real para obtener resultados probables. Por el contrario, la IA utiliza técnicas de ciencia de datos aplicadas y otros algoritmos para componer y ejecutar sistemas complejos basados en máquinas que se aproximan a la inteligencia humana.
La ciencia de datos también se puede utilizar en aplicaciones distintas de la IA y la informática.
Objetivos
El objetivo de la ciencia de datos es aplicar los modelos y métodos estadísticos e informáticos existentes para comprender los puntos de interés o patrones en los datos recopilados. Los resultados están predeterminados y son fáciles de definir desde el principio. Por ejemplo, puede usar los datos para predecir futuras ventas o identificar cuándo una pieza de maquinaria está lista para repararla.
El objetivo de la IA es utilizar computadoras para producir un resultado a partir de datos nuevos y complejos que sea indistinguible del razonamiento humano inteligente. Los resultados son genéricos y difíciles de definir: por ejemplo, generar texto creativo o generar imágenes a partir de texto. Los detalles del conjunto de problemas son demasiado grandes para definirlos con precisión y el sistema de IA interpreta el problema por sí solo.
Ámbito
La ciencia de datos tiene un alcance menor, ya que el resultado está predeterminado. El proceso comienza por identificar las preguntas que pueden responderse a partir de los datos. El ámbito incluye:
- Recopilación y procesamiento previo de datos.
- Aplicar modelos y algoritmos apropiados a los datos para responder a estas preguntas.
- Interpretación de los resultados.
Por el contrario, la IA tiene un alcance mucho más amplio y los pasos varían en función del problema que se quiera resolver. El proceso comienza por identificar una tarea manual que requiera mucha mano de obra o una tarea de razonamiento compleja que los humanos realicen con éxito y que queremos que la máquina replique. El ámbito puede incluir:
- Análisis exploratorio de datos.
- División de la tarea en componentes algorítmicos para formar un sistema.
- Recopilación de datos de prueba para revisar y perfeccionar la idoneidad del flujo lógico y la complejidad del sistema.
- Prueba del sistema.

Methods
La ciencia de datos tiene una amplia gama de técnicas para modelar datos. La selección de la técnica correcta depende de los datos y de la pregunta que se plantee. Estos incluyen la regresión lineal, la regresión logística, la detección de anomalías, la clasificación binaria, los clústeres de k-means, el análisis de componentes principales y muchos más. Un análisis estadístico aplicado de forma incorrecta producirá resultados inesperados.
Las aplicaciones de IA suelen basarse en componentes complejos, diseñados con anterioridad y desarrollados como productos. Estos pueden incluir reconocimiento facial,procesamiento del lenguaje natural, aprendizaje por refuerzo, gráficos de conocimiento, inteligencia artificial generativa (IA generativa ) y muchos más.
Aplicaciones: ciencia de datos en comparación con inteligencia artificial
La ciencia de datos se puede aplicar en cualquier lugar donde haya suficientes datos de calidad y un modelo para ayudar a responder una pregunta en particular. Las aplicaciones incluyen lo siguiente:
- Previsión de demanda de ventas
- Detección de fraude
- Probabilidades de resultados deportivos
- Evaluación de riesgos
- Previsión del consumo energético
- Optimización de ingresos
- Procesos de selección de candidatos
Las aplicaciones de IA son casi infinitas. Entre las aplicaciones más populares se incluyen las siguientes:
- Líneas de producción robóticas
- Chatbots
- Sistemas de reconocimiento biométrico
- Análisis de imágenes médicas
- Mantenimiento predictivo
- Urbanismo
- Personalización de marketing
Carreras: ciencia de datos en comparación con inteligencia artificial
El enfoque principal de un científico de datos suele ser técnico, ya que trabaja en profundidad en los datos. Los científicos de datos pueden trabajar en la recopilación y el procesamiento de datos, elegir los modelos correctos para los datos e interpretar los resultados para hacer recomendaciones. El trabajo se puede realizar dentro de software o sistemas específicos, o incluso en los propios sistemas de construcción.
Tipos de funciones
Los trabajos de ciencia de datos incluyen científicos de datos, analistas de datos, ingenieros de datos, ingenieros de machine learning, científicos de investigación, especialistas en visualización de datos, roles de analistas específicos de campo y más. La IA también abarca todas estas funciones. Sin embargo, dado que el alcance del campo es tan amplio, hay muchos roles asociados adicionales y áreas de enfoque laboral, como desarrollador de software, gerente de producto, especialista en marketing, examinador de inteligencia artificial, ingeniero de inteligencia artificial y más.
Conjunto de habilidades
Los científicos de datos tienen habilidades en la aplicación práctica de métodos estadísticos y algorítmicos para calificar y analizar datos para encontrar información relevante. Los científicos de datos requieren una formación en matemáticas estadísticas e informática y dominio de las herramientas aplicables.
Dependiendo del rol dentro de la IA, el conjunto de habilidades requeridas puede ser más técnico o basado en habilidades blandas. En algunos puestos, es posible que no se requiera experiencia técnica. Por ejemplo, un desarrollador de software de inteligencia artificial necesitaría conocimientos prácticos de los lenguajes de programación, bibliotecas y herramientas relevantes. Sin embargo, un examinador de IA para una herramienta de IA generativa requeriría habilidades lingüísticas, pensamiento creativo y comprensión de cómo los usuarios deben interactuar con el sistema.
Progresión profesional
A medida que las herramientas y los flujos de trabajo de la ciencia de datos se vuelven más automatizados y productivos, la cantidad de funciones de ciencia de datos pura disminuye. Los profesionales de la ciencia de datos que buscan funciones de ciencia de datos pura tienden a utilizar aplicaciones académicas y de vanguardia. Las funciones de analista en las que el científico de datos es el propietario del funcionamiento de las herramientas siguen siendo relevantes. Desde un puesto junior, los científicos de datos obtienen puestos más altos, pasan a la gestión de personas o proyectos e incluso ascienden a directores de datos.
Dependiendo del enfoque de la función de IA en sí, se puede esperar una progresión profesional similar. Puede ascender a director de tecnología, director de marketing, director de productos, etc. Pensar críticamente sobre qué trabajos se automatizarán en los próximos diez años puede ayudar a preparar una carrera profesional para el futuro.
Resumen de las diferencias: ciencia de datos comparada con inteligencia artificial
| Ciencia de datos |
Inteligencia artificial |
|
| ¿Qué es? |
El uso de modelos estadísticos y algorítmicos para obtener información a partir de los datos. |
Un término de amplio espectro que define a aquellas aplicaciones basadas en máquinas que imitan la inteligencia humana. |
| Más adecuada para lo siguiente: |
Responder a una pregunta a partir de un conjunto de datos. |
Completar una tarea humana compleja con eficiencia. |
| Methods |
Regresión lineal, regresión logística, detección de anomalías, clasificación binaria, agrupación en clústeres k-means, análisis de componentes principales y más. |
Reconocimiento facial, procesamiento del lenguaje natural, aprendizaje por refuerzo, gráficos de conocimiento, IA generativa y más. |
| Ámbito |
Preguntas predefinidas que se pueden responder a partir de los datos. |
Amplio y difícil de definir, basado en tareas. |
| Implementación |
Utiliza una variedad de herramientas diferentes para capturar, limpiar, modelar, analizar e informar sobre los datos. |
Depende de la tarea. Por lo general, se basa en componentes complejos, prefabricados y desarrollados como productos. |
¿Cómo puede ayudarlo AWS con sus requisitos de ciencia de datos e inteligencia artificial?
AWS cuenta con una gama completa de productos y servicios de ciencia de datos e inteligencia artificial diseñados para ayudarlo a fortalecer y hacer crecer su inteligencia y análisis de datos organizacionales e individuales.
Esto incluye modelos de ciencia de datos e inteligencia artificial basados en la API para datos estructurados y no estructurados y entornos totalmente gestionados que permiten la creación y el despliegue integrales de soluciones de ciencia de datos e inteligencia artificial.
- Amazon SageMaker Studio es un entorno de desarrollo integrado (IDE) que incluye una pila de herramientas diseñadas especialmente para desarrollar soluciones de ciencia de datos y aprendizaje automático.
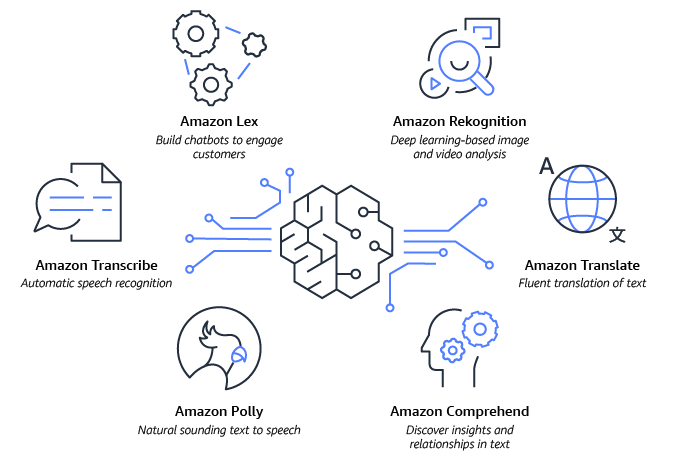
- Amazon Lex ayuda a crear sus propios chatbots con IA conversacional.
- Amazon Rekognition ofrece capacidades de visión artificial (CV) previamente entrenadas y personalizables para extraer información a partir de las imágenes y los videos.
- Amazon Comprehend le ayuda a obtener y comprender información valiosa a partir del texto de los documentos.
- Amazon Personalize aprovecha el aprendizaje automático para ayudar a personalizar la experiencia del cliente.
- Amazon Forecast ayuda a realizar previsiones de series temporales.
- Amazon Fraud Detector ayuda a crear, implementar y gestionar modelos de detección de fraudes.
AWS también ofrece una lista cada vez mayor de soluciones de IA generativa de primer nivel que pueden crear nuevos contenidos e ideas, como conversaciones, historias, imágenes, vídeos y música. Las soluciones de IA generativa incluyen:
- Amazon Bedrock ayuda a las organizaciones a crear y escalar soluciones de IA generativa.
- AWS Trainium ayuda a entrenar modelos de IA generativa con mayor rapidez.
- Amazon Q Developer es un asistente con tecnología de IA generativa que se utiliza para el desarrollo de software.
Para comenzar a utilizar ciencia de datos e inteligencia artificial en AWS, cree una cuenta hoy mismo.