



Qual è la differenza tra Cassandra e HBase?
Apache Cassandra e Apache HBase sono database NoSQL che archiviano i dati in un formato non tabulare. Entrambi archiviano i dati come archivi chiave-valore su un'infrastruttura di big data per gestire enormi volumi di dati in modo accurato ed efficiente. Tuttavia, presentano differenze architettoniche che si adattano meglio ai diversi casi d'uso. Ad esempio, Cassandra offre prestazioni di lettura e scrittura veloci, mentre HBase offre una maggiore coerenza dei dati. Inoltre, HBase è più efficace nella gestione di grandi set di dati di tipo sparse. Le organizzazioni utilizzano Cassandra e HBase per diversi casi d'uso dei big data.
Somiglianze tra Cassandra e HBase
Cassandra ed HBase sono due database NoSQL in grado di archiviare, elaborare e recuperare miliardi di set di dati. Presentano somiglianze sovrapposte nelle seguenti aree.
Applicazione di big data
Con Cassandra ed HBase è possibile archiviare enormi volumi di dati non relazionali e non strutturati. Si differenziano da un sistema di database tradizionale, che memorizza i dati in semplici righe di colonne. È possibile utilizzare Cassandra ed HBase per archiviare immagini, audio, video e altri tipi di dati non strutturati per l'elaborazione su larga scala.
Open source
L'Apache Software Foundation pubblica e gestisce Cassandra ed HBase come progetti open source. HBase è stato sviluppato a partire dal concetto introdotto da Google BigTable e rilasciato al pubblico da Apache nel 2008. Cassandra è un'iniziativa creata per risolvere i problemi di ricerca nella casella di posta di Facebook. Utilizza alcune funzionalità di BigTable e altre di Amazon Dynamo.
Scopri di più sull'open source
Scalabilità
È possibile dimensionare HBase per soddisfare crescenti richieste di dati aggiungendo più server regionali al cluster HBase. Il sistema di database NoSQL può quindi distribuire i nodi di dati in nuove regioni quando superano una determinata capacità. Un cluster Cassandra può supportare anche più nodi per dimensionare le proprie capacità di gestione dei dati. Aggiungendo più nodi, è possibile distribuire efficacemente i dati in modo uniforme e prevenire colli di bottiglia del traffico.
Ripristino dei dati
I nodi di dati sia su Cassandra che su HBase sono tolleranti ai guasti. Su Cassandra, ogni nodo supporta la replica dei dati. Un'operazione di scrittura viene inviata automaticamente a tutti i nodi assegnati ai dati particolari. HBase ha un approccio simile alla duplicazione dei dati, automatizzata dal File system distribuito Hadoop (HDFS) su cui viene eseguita. L'HDFS crea e mantiene duplicati di dati su server diversi. Entrambi i database NoSQL duplicano i nodi di dati in diverse reti fisiche in base al fattore di replica per ridurre i rischi di guasti a livello di rete.
Percorso di scrittura
Cassandra ed HBase organizzano i dati in colonne. Durante l'archiviazione di dati, ogni database cerca la famiglia di colonne appropriata, che tiene insieme le informazioni correlate. Entrambi i database scrivono i dati anche nei file di log quando il database li aggiunge o li archivia nella colonna.
Differenze architettoniche: Cassandra e HBase
Cassandra ed HBase operano con caratteristiche diverse del teorema CAP. Il teorema CAP specifica che i sistemi distribuiti possono possedere due dei seguenti tratti in un dato momento:
- Consistenza
- Disponibilità
- Tolleranza della partizione
Poiché la tolleranza della partizione è obbligatoria per i database che memorizzano set di dati di grandi dimensioni, Cassandra ed HBase differiscono per disponibilità e coerenza. Cassandra ha un'elevata disponibilità e tolleranza della partizione grazie alla sua disposizione dei nodi peer-to-peer. HBase fornisce coerenza con la tolleranza della partizione perché un singolo primario HBase replica i dati su tutti i nodi.
Di seguito, spiegheremo ulteriori differenze architettoniche nel modo in cui entrambi i database gestiscono le richieste di dati.
Modello di dati
Cassandra ed HBase organizzano i dati in gruppi, righe e colonne, ma ogni database lo fa con layout diversi. In Cassandra, le colonne di dati correlati vengono archiviate in righe in una categoria più ampia chiamata keyspace. Ad esempio, un database Cassandra potrebbe contenere i seguenti keyspace, famiglie di colonne e disposizione delle celle:
- Keyspace: CustomerOrders
- Famiglia di colonne: Client
- ID, FirstName, LastName
- Famiglia di colonne: Orders
- ID, Item, Price
- Famiglia di colonne: Client
La famiglia di colonne Client si trova in una partizione sopra la famiglia di colonne Orders. Nelle applicazioni pratiche, un keyspace raggruppa più colonne della famiglia.
L'architettura HBase ha un layout simile a quello dei database relazionali tradizionali. Invece di avere un ID per ogni famiglia di colonne, HBase utilizza chiavi di riga sequenziali in una tabella. Quindi dispone le colonne che appartengono alla stessa famiglia di colonne una accanto all'altra per un facile recupero da DataEase. Ecco un esempio:
- Tabella: CustomerOrders
- Chiave della riga, famiglia di colonne: Client {First Name, LastName}, famiglia di colonne: Order {Item, Price}
Scopri di più sui database relazionali
Componenti chiave
Cassandra utilizza una tecnica chiamata hashing coerente per consentire a ciascun nodo di trovare rapidamente dati specifici nella propria rete peer-to-peer. I suoi componenti principali includono memtable, log di commit e tabelle SS. Insieme, costituiscono il percorso di scrittura per i nodi, i data center e i cluster dell'architettura di Cassandra.
HBase si trova sulla parte superiore dell'HDFS. Utilizza il primario HBase, il server regionale e Zookeeper per offrire la gestione dei dati.
Cassandra fornisce la gestione e l'archiviazione di dati in modo indipendente, mentre HBase richiede sistemi esterni per le funzionalità di archiviazione di dati.
Design principale
Cassandra funziona sull'architettura attiva-attiva, in cui ogni nodo risponde alle scritture e alle richieste. Anche se un particolare nodo non memorizza i dati richiesti, li recupera da altri nodi con un metodo di comunicazione peer-to-peer chiamato protocollo gossip.
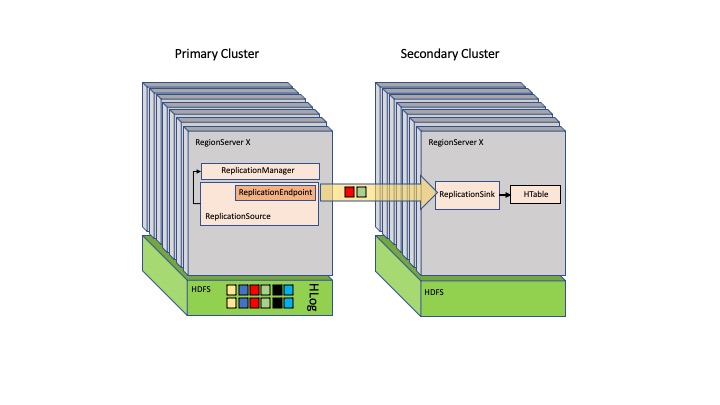
HBase utilizza una configurazione primaria-secondaria, in cui il primario HBase ha il controllo sui server regionali di altri nodi. L'architettura di HBase presenta un singolo punto di errore se non ci sono repliche del primario HBase. È possibile duplicare più nodi primari HBase, ma solo uno si occupa di tutti i server regionali.
L'immagine seguente mostra la configurazione primaria-secondaria su HBase.
Linguaggio di query
Cassandra consente la manipolazione dei dati nel database con il Cassandra Query Language (CQL), utilizzato per aggiungere, rimuovere o aggiornare i record in istruzioni descrittive simili a SQL. L'HBase Query Language è costituito da comandi shell di base il cui apprendimento richiede più impegno.
Prestazioni: Cassandra vs. HBase
Cassandra ed HBase forniscono un accesso ad alta velocità a set di dati di grandi dimensioni per l'analisi dei big data. I database mostrano differenze di prestazioni nei seguenti aspetti.
Latenza
La latenza è l'intervallo di tempo tra l'invio di un'istruzione al sistema di database e l'archiviazione o il recupero dei dati. In genere, HBase mostra una latenza inferiore all'aumentare del numero di letture e scritture di dati. Vale il contrario per Cassandra, che mostra ritardi maggiori man mano che recupera più dati.
Prestazioni
La velocità di trasmissione effettiva misura il numero di operazioni di lettura o scrittura gestite da un database ogni secondo. HBase mantiene una velocità di trasmissione effettiva costante di 100.000-200.000 operazioni, ma dimostra un aumento una volta raggiunte 250.000 operazioni. La velocità di trasmissione effettiva di Cassandra aumenta man mano che scrive o legge più dati.
Prestazioni di lettura
Un'operazione di lettura su Cassandra implica la ricerca della posizione esatta dei dati memorizzati sulla tabella di partizione. Se la ricerca riguarda una chiave secondaria o una tabella non di partizione, Cassandra impiega più tempo a cercare ogni nodo del cluster. Inoltre, le incongruenze dei dati si verificano quando diversi nodi contengono versioni diverse degli stessi dati.
HBase ha prestazioni di lettura migliori rispetto a Cassandra perché scrive tutti i dati su un singolo server. A differenza di Cassandra, la lettura dei dati su HBase non richiede che il sistema di database cerchi in una tabella di partizione. L'HDFS utilizzato da HBase per archiviare i dati fornisce filtri bloom e cache a blocchi, che accelerano il recupero dei dati.
Prestazioni di scrittura
Cassandra completa un'operazione di scrittura più velocemente di Hbase. e permette di scrivere dati nel log e nella cache contemporaneamente, a differenza di HBase. Invece, l'applicazione client HBase passa attraverso Zookeeper per avviare un'operazione di scrittura, dove il primario HBase fornisce l'indirizzo per l'archiviazione di dati. I passaggi aggiuntivi su HBase rallentano il processo di scrittura dei dati.
Altre differenze chiave tra Cassandra ed HBase
È possibile utilizzare sia Cassandra che HBase per creare applicazioni di data science, ma la scelta dell'uno rispetto all'altro può essere influenzata da lievi differenze.
Sicurezza
Con Cassandra, è possibile regolare l'accesso al livello delle righe dei record. Inoltre, fornisce la crittografia SSL per proteggere lo scambio di dati tra i nodi. A differenza di Cassandra, HBase fornisce funzionalità aggiuntive di crittografia a livello di cella o di crittografia e autenticazione.
Partizionamento dei dati
Cassandra supporta il partizionamento ordinato e può eseguire la scansione dei record ordinati in sequenza utilizzando una colonna come chiave di partizione. Sebbene questo possa essere utile, il partizionamento ordinato complica il bilanciamento del carico, con più scritture che avvengono su un singolo nodo. Una tabella HBase non supporta il partizionamento ordinato.
Comunicazione tra nodi
Nell'architettura di Cassandra, i nodi seed sono i punti chiave per le comunicazioni tra cluster. e utilizzano il protocollo gossip per spostare i dati tra diversi cluster. HBase utilizza un nodo primario HBase attivo per coordinare la comunicazione tra diversi server regionali. In questa architettura, lo spostamento dei dati è negoziato dal protocollo Zookeeper.
Quando utilizzare Cassandra ed HBase
I database Cassandra e HBase possono aiutare diversi tipi di applicazioni di big data. Successivamente, condividiamo quale database distribuito funzionerebbe meglio dell'altro in circostanze diverse.
Disponibilità vs. coerenza
Cassandra è adatto per casi d'uso che richiedono una scrittura frequente dei dati, ma non è ottimizzato per il loro aggiornamento o la loro eliminazione con frequenza. Ad esempio, le organizzazioni utilizzano Cassandra per creare sistemi di messaggistica, soluzioni interattive di elaborazione dei dati e archiviazione di dati dei sensori in tempo reale. HBase è più indicato per le applicazioni che richiedono coerenza ed elaborazione frequente dei dati. Ad esempio, le soluzioni bancarie, sanitarie e di telecomunicazione utilizzano HBase per analizzare grandi volumi di dati.
Configurazione del database
Cassandra è più facile da configurare perché è un prodotto autonomo completo di tutti i componenti del database necessari. A differenza di Cassandra, per funzionare HBase si affida a diversi componenti Hadoop, come Zookeeper, HDFS primario e HDFS DataNode. La configurazione potrebbe essere semplice, ma mantenere più interdipendenze potrebbe rivelarsi difficile nelle applicazioni reali. Se è già in utilizzo l'infrastruttura Hadoop, la migrazione ad HBase potrebbe risultare più semplice rispetto alla migrazione a Cassandra.
Riepilogo delle differenze: Cassandra e HBase
| Cassandra |
HBase |
|
| Design principale |
Utilizza l'architettura attiva-attiva. Tutti i nodi elaborano le richieste di lettura/scrittura. |
Utilizza l'architettura primaria-secondaria. Il primario HBase controlla diversi server regionali. |
| Componenti chiave |
Memtable, log di commit e tabelle SS. |
Il primario HBase, server regionale e Zookeeper. |
| Modello di dati |
Archivia le righe delle famiglie di colonne correlate nel keyspace. |
Famiglie di colonne disposte orizzontalmente con una chiave di riga sequenziale. |
| Linguaggio di query |
Utilizza il linguaggio di query di Cassandra. |
Utilizza il comando shell (interprete di comandi). |
| Latenza |
Latenza più elevata con più recuperi di dati. |
Latenza ridotta con più operazioni sui dati. |
| Prestazioni |
La velocità di trasmissione effettiva aumenta con l'aumento delle operazioni sui dati. |
La velocità di trasmissione effettiva aumenta dopo un certo numero di operazioni. |
| Prestazioni di lettura |
Lettura lenta. Fa riferimento alla tabella delle partizioni per la posizione di lettura. Possono verificarsi incongruenze nei dati. |
Migliori prestazioni di lettura e coerenza dei dati. |
| Prestazioni di scrittura |
Migliori prestazioni di scrittura. Scrive contemporaneamente nel log e nella cache. |
Passaggi aggiuntivi. Passa attraverso Zookeeper e il primario HBase. |
| Sicurezza |
Regola l'accesso fino al livello di ruolo. |
Regola l'accesso fino al livello di cella. |
| Partizionamento dei dati |
Supporta il partizionamento ordinato. |
Non supporta il partizionamento ordinato. |
| Comunicazione tra nodi |
Utilizza il protocollo gossip. |
Utilizza il protocollo Zookeeper. |
In che modo AWS può aiutarti a soddisfare i requisiti di Cassandra e HBase?
Amazon Web Services (AWS) fornisce servizi di database cloud scalabili da utilizzare per implementare tecnologie di data science in modo efficiente e conveniente. Invece di effettuare manualmente il provisioning dell'infrastruttura sottostante, è possibile utilizzare i seguenti servizi AWS per supportare i database Cassandra e HBase:
- Amazon Keyspaces (per Apache Cassandra) è un servizio di database online per l'esecuzione di carichi di lavoro Cassandra a elevata velocità di trasmissione effettiva. Con Amazon Keyspaces, è possibile dimensionare le applicazioni mantenendo i tempi di risposta in millisecondi a una cifra.
- Con Amazon EMR, è possibile implementare cluster HBase per applicazioni di elaborazione dati su larga scala. L'esecuzione di HBase su EMR migliora la ripristinabilità dei dati eseguendo il backup dei dati archiviati su Amazon Simple Storage Service (Amazon S3).
Inizia subito a utilizzare le analisi dei big data su AWS creando un account.