



Cos’è il boosting nel machine learning?
Il boosting è un metodo utilizzato nel machine learning per ridurre gli errori nell'analisi predittiva dei dati. I data scientst addestrano software di machine learning, chiamati modelli di machine learning, su dati etichettati per formulare ipotesi su dati non etichettati. Un singolo modello di machine learning potrebbe causare errori di previsione a seconda dell'accuratezza del set di dati di addestramento. Ad esempio, se un modello di identificazione di gatti è stato addestrato solo su immagini di gatti bianchi, occasionalmente potrebbe identificare erroneamente un gatto nero. Il boosting tenta di superare questo problema addestrando più modelli in sequenza per migliorare l'accuratezza del sistema generale.
Perché il boosting è importante?
Il boosting migliora l’accuratezza predittiva e la performance dei modelli delle mcchine convertendo più learner deboli in un singolo modello forte di apprendimento. I modelli di machine learning possono essere learner deboli o forti:
Learner deboli
I learner deboli hanno bassa accuratezza predittiva, simile all’ipotesi casuale. Sono soggetti all’overfitting, ovvero non possono classificare i dati che si allontanano troppo dal set di dati originale. Ad esempio, se addestri il modello all’identificazione di gatti come animali con le orecchie a punta, esso potrebbe fallire nel riconoscere un gatto con le orecchie arricciate.
Learner forti
I learner forti hanno un’accuratezza predittiva maggiore. Il boosting converte un sistema di learner deboli in un unico sistema di learning forte. Ad esempio, per identificare l’immagine del gatto, esso combina un learner debole che formula un'ipotesi sulle orecchie a punta e un altro learner che formula un'ipotesi sugli occhi a forma di gatto. Dopo aver analizzato l’immagine dell’animale cercando le orecchie a punta, il sistema lo analizza un'altra volta per cercare gli occhi a forma di gatto. Ciò migliora l’accuratezza generale del sistema.
Come funziona il boosting?
Per capire il funzionamento del boosting, illustriamo in che modo i modelli di machine learning prendono delle decisioni. Sebbene vi siano molteplici variazioni nell’implementazione, i data scientist spesso utilizzano il boosting con algoritmi ad albero decisionale:
Alberi decisionali
Gli alberi decisionali sono strutture di dati in machine learning che funzionano dividendo il set di dati in sottogruppi sempre più piccoli sulla base delle loro caratteristiche. L’idea è che gli alberi decisionali dividano i dati ripetutamente finché non sia rimasta solo una classe. Ad esempio, l'albero potrebbe porre una serie di domande con risposta sì/no e dividere i dati in categorie ad ogni passaggio.
Metodo ensemble di boosting
Il boosting crea un modello ensemble combinando sequenzialmente molti alberi decisionali deboli. Attribuisce peso all’output di singoli alberi. Poi dà alle classificazioni errate del primo albero decisionale un peso maggiore e un input all'albero successivo. Dopo numerosi circoli, il metodo boosting combina queste regole deboli in una sola regola predittiva potente.
Il boosting a confronto col bagging
Boosting e bagging sono i due metodi comuni ensemble che migliorano l’accuratezza della previsione. La principale differenza tra questi metodi di apprendimento è il metodo di addestramento. Nel bagging i data scientist migliorano l’accuratezza dei learner deboli addestrando molti di questi una sola volta in molteplici set di dati. Al contrario, il boosting addestra i learner deboli uno dopo l’altro.
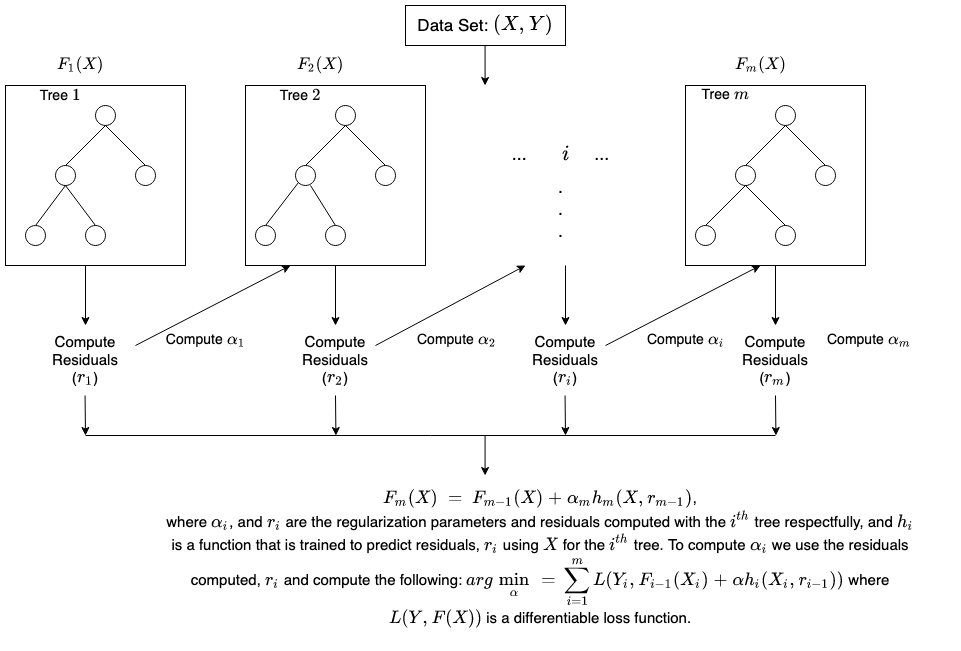
Come si svolge l’addestramento nel boosting?
Il metodo di addestramento varia in base al tipo di elaborazione boosting, detta algoritmo di boosting. Ad ogni modo, un algoritmo necessita delle seguenti fasi generali per addestrare il modello di boosting:
Fase 1
L’algoritmo del boosting assegna ugual peso a ogni campione dati. Fornisce i dati al primo modello di machine, l’algoritmo base. L’algoritmo base fa ipotesi per ogni campione di dati.
Fase 2
L’algoritmo di boosting valuta le previsioni del modello e aumenta il peso dei campioni con un errore più significativo. Assegna inoltre un peso sulla base della prestazione del modello. Un modello che genera previsioni eccellenti avrà maggiore influenza sulla decisione finale.
Fase 3
L’algoritmo trasferisce i dati pesati all'albero decisionale successivo.
Fase 4
L’algoritmo ripete le fasi 2 e 3 finché le istanze di errori di addestramento si trovano al di sotto di una certa soglia.
In che modo AWS può rivelarsi utile per il boosting?
I servizi di rete AWS sono pensati per offrire alle aziende:
Amazon SageMaker
Amazon SageMaker riunisce un'ampia gamma di capacità costruite appositamente per il machine learning. Si può utilizzare per preparare, costruire, addestrare e implementare rapidamente modelli di machine learning di alta qualità.
Amazon SageMaker Canvas
Amazon SageMaker Canvas elimina il pesante fardello della costruzione di modelli di machine learning e aiuta a costruire e addestrare automaticamente modelli basati sui dati. Con SageMaker Canvas, si fornisce un set di dati tabulare e si seleziona la colonna di destinazione su cui fare previsioni, che può essere un numero o una categoria. SageMaker Autopilot vaglierà automaticamente diverse soluzioni per trovare il modello migliore. È quindi possibile implementare direttamente il modello in produzione con un solo clic o migliorarne ulteriormente la qualità con le soluzioni consigliate tramite Amazon SageMaker Studio.
Addestramento del modello Amazon SageMaker
Addestramento dei modelli di Amazon SageMaker semplifica l'ottimizzazione dei modelli di machine learning tramite l'acquisizione in tempo reale dei parametri di addestramento e l'invio di allarmi quando rileva errori. In questo modo è possibile correggere immediatamente le previsioni del modello come l'identificazione errata di un'immagine.
Amazon SageMaker offre metodi rapidi e semplici per l'addestramento di modelli di deep learning e set di dati di grandi dimensioni. Le librerie di addestramento distribuite di SageMaker addestrano più rapidamente set di dati di grandi dimensioni.
Inizia oggi stesso a utilizzare Amazon SageMaker creando un account AWS.