



Cosa sono le integrazioni nel machine learning?
Gli embedding sono rappresentazioni numeriche di oggetti del mondo reale utilizzate dai sistemi di machine learning (ML) e di intelligenza artificiale (IA) per comprendere domini di conoscenza complessi, analogamente al modo in cui lo fanno gli esseri umani. Ad esempio, gli algoritmi di calcolo comprendono che la differenza tra 2 e 3 è 1, il che indica una stretta relazione tra 2 e 3 rispetto a 2 e 100. Tuttavia, i dati del mondo reale includono relazioni più complesse. Ad esempio, un nido di uccelli e una tana di leoni sono coppie analoghe, mentre giorno-notte sono termini opposti. Le integrazioni convertono gli oggetti del mondo reale in rappresentazioni matematiche complesse che acquisiscono proprietà e relazioni intrinseche tra i dati del mondo reale. L'intero processo è automatizzato: i sistemi di intelligenza artificiale creano autonomamente le integrazioni durante l'addestramento e le utilizzano quando necessario per completare nuove attività.
Perché le integrazioni sono importanti?
Le integrazioni consentono ai modelli di deep learning di comprendere in modo più efficace i domini di dati del mondo reale. Semplificano il modo in cui vengono rappresentati i dati del mondo reale, pur mantenendo le relazioni semantiche e sintattiche. Ciò consente agli algoritmi di machine learning di estrarre ed elaborare tipi di dati complessi e abilitare applicazioni di intelligenza artificiale innovative. Le seguenti sezioni descrivono alcuni fattori importanti.
Riduzione della dimensionalità dei dati
I data scientist utilizzano le integrazioni per rappresentare dati ad alta dimensionalità in uno spazio a bassa dimensionalità. In data science, il termine dimensionalità si riferisce in genere a una funzionalità o a un attributo dei dati. I dati a dimensionalità superiore nell'ambito dell'intelligenza artificiale si riferiscono a set di dati con molte funzionalità o attributi che definiscono ciascun punto dati. Ciò può significare decine, centinaia o persino migliaia di dimensioni. Ad esempio, un'immagine può essere considerata un dato ad alta dimensionalità perché ogni valore di colore del pixel rappresenta una dimensione separata.
Quando presentati con dati ad alta dimensionalità, i modelli di deep learning richiedono più potenza computazionale e tempo per apprendere, analizzare e dedurre con precisione. Le integrazioni riducono il numero di dimensioni identificando somiglianze e pattern tra le varie funzionalità. Di conseguenza, si riducono le risorse di calcolo e il tempo richiesti per elaborare i dati grezzi.
Addestramento di grandi modelli linguistici
Gli embedding migliorano la qualità dei dati durante l'addestramento dei modelli linguistici di grandi dimensioni (LLM). Ad esempio, i data scientist utilizzano le integrazioni per pulire i dati di addestramento dalle irregolarità che influiscono sull'apprendimento dei modelli. Gli ingegneri di ML possono anche riutilizzare modelli preaddestrati aggiungendo nuove integrazioni per l'apprendimento per trasferimento, il che richiede il perfezionamento del modello di base con nuovi set di dati. Con le integrazioni, gli ingegneri possono mettere a punto un modello per set di dati personalizzati provenienti dal mondo reale.
Creare applicazioni innovative
Le integrazioni consentono nuove applicazioni di deep learning e intelligenza artificiale generativa (IA generativa). Diverse tecniche di integrazione applicate all'architettura di rete neurale permettono di sviluppare, addestrare e implementare modelli di intelligenza artificiale accurati in vari campi e applicazioni. Ad esempio:
- Con le integrazioni di immagini, gli ingegneri possono creare applicazioni di visione artificiale ad alta precisione per il rilevamento oggetti, riconoscimento immagini e altre attività legate alla visualizzazione.
- Con le integrazioni di parole, i software di elaborazione del linguaggio naturale possono comprendere in maniera più accurata il contesto e le relazioni tra le parole.
- Le integrazioni di grafi estraggono e classificano le informazioni correlate dai nodi interconnessi per supportare l'analisi di rete.
Modelli di visione artificiale, i chatbot di intelligenza artificiale e i sistemi di suggerimento di intelligenza artificiale utilizzano tutti le integrazioni per completare attività complesse che imitano l'intelligenza umana.
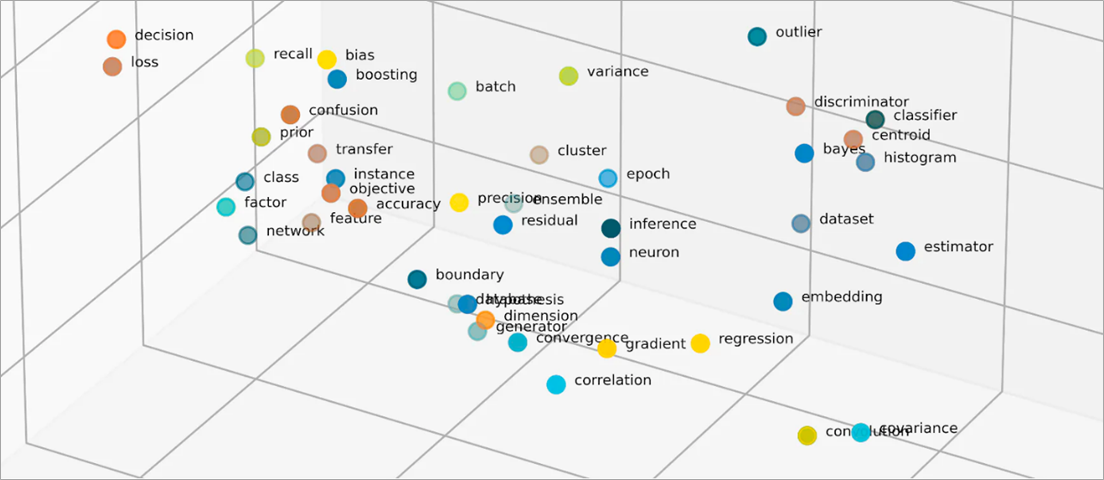
Cosa sono i vettori nelle integrazioni?
I modelli di machine learning non sono in grado di interpretare le informazioni in modo intelligibile nel loro formato grezzo e richiedono dati numerici come input. Utilizzano le integrazioni di reti neurali per convertire informazioni di parole reali in rappresentazioni numeriche chiamate vettori. I vettori sono valori numerici che rappresentano le informazioni in uno spazio multidimensionale. Aiutano i modelli di machine learning a trovare somiglianze tra gli elementi distribuiti in modo sparso.
Ogni oggetto da cui un modello di machine learning apprende ha diverse caratteristiche o funzionalità. A titolo di esempio, si considerino i seguenti film e programmi TV. Ognuno di essi è caratterizzato per genere, tipo e anno di uscita.
Il convegno (Horror, 2023, Film)
Upload (Commedia, 2023, serie TV, 3 stagioni)
I racconti della cripta (Horror, serie TV, 7 stagioni, 1989)
Dream Scenario - Hai mai sognato quest'uomo? (Commedia horror, 2023, film)
I modelli di machine learning possono interpretare variabili numeriche come l'anno, ma non possono confrontare quelle non numeriche come genere, tipologia, episodi e stagioni complete. I vettori di integrazione codificano dati non numerici in una serie di valori che i modelli di ML possono comprendere e mettere in relazione. Ad esempio, di seguito è riportata un'ipotetica rappresentazione dei programmi televisivi elencati in precedenza.
Il convegno (1.2, 2023, 20.0)
Upload (2.3, 2023, 35.5)
I racconti della cripta (1.2, 1989, 36.7)
Dream Scenario - Hai mai sognato quest'uomo? (1.8, 2023, 20.0)
Il primo numero del vettore corrisponde a un genere specifico. Un modello di machine learning riscontrerebbe che Il convegno e I racconti della cripta sono accomunati dallo stesso genere. Allo stesso modo, il modello troverà più relazioni tra Upload e I racconti della cripta in base al terzo numero, che rappresenta il formato, le stagioni e gli episodi. Con l'introduzione di più variabili, è possibile perfezionare il modello per condensare più informazioni in uno spazio vettoriale più piccolo.
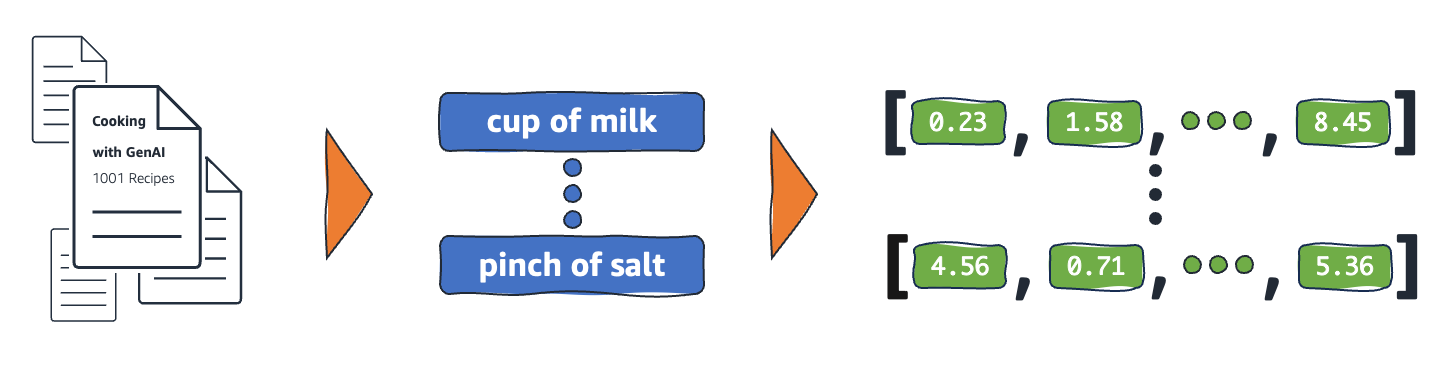
Come funzionano le integrazioni?
Le integrazioni convertono i dati grezzi in valori continui che i modelli di ML possono interpretare. Convenzionalmente, i modelli di ML utilizzano la codifica one-hot per mappare le variabili categoriche e renderle utilizzabili per l'apprendimento. Il metodo di codifica suddivide ogni categoria in righe e colonne e assegna loro valori binari. Si considerino le seguenti categorie di prodotti e il loro prezzo.
| Frutta |
Prezzo |
| Apple |
5,00 |
| Orange |
7,00 |
| Carota |
10,00 |
Se si rappresentano i valori con la codifica one-hot, si ottiene la seguente tabella.
| Apple |
Orange |
Pera |
Prezzo |
| 1 |
0 |
0 |
5,00 |
| 0 |
1 |
0 |
7,00 |
| 0 |
0 |
1 |
10,00 |
La tabella è rappresentata matematicamente come vettori [1,0,0,5.00], [0,1,0,7.00] e [0,0,1,10.00].
La codifica one-hot espande i valori dimensionali di 0 e 1 senza fornire informazioni utili a far sì che i modelli correlino i diversi oggetti. Ad esempio, il modello non riesce a trovare somiglianze tra mela e arancia pur essendo frutti, né può differenziare arancia e carota come frutta e verdura. Aggiungendo più categorie all'elenco, la codifica produce variabili scarsamente distribuite con molti valori vuoti che occupano un enorme spazio di memoria.
Le integrazioni vettorializzano gli oggetti in uno spazio a bassa dimensionalità, rappresentando le somiglianze tra oggetti con valori numerici. Le integrazioni di reti neurali garantiscono che il numero di dimensioni rimanga gestibile con l'espansione di funzionalità di input. Le funzionalità di input sono tratti di oggetti specifici che un algoritmo di ML ha il compito di analizzare. La riduzione della dimensionalità consente alle integrazioni di mantenere le informazioni utilizzate dai modelli di ML per trovare somiglianze e differenze tra i dati di input. I data scientist possono anche visualizzare le integrazioni in uno spazio bidimensionale per comprendere meglio le relazioni tra gli oggetti distribuiti.
Cosa sono i modelli di integrazione?
I modelli di integrazione sono algoritmi addestrati per incapsulare informazioni in rappresentazioni dense in uno spazio multidimensionale. I data scientist utilizzano modelli di integrazione per consentire ai modelli di ML di comprendere e ragionare con dati ad alta dimensionalità. Si tratta di modelli di integrazione comunemente utilizzati nelle applicazioni di ML.
Analisi delle componenti principali
L'analisi delle componenti principali (PCA) è una tecnica di riduzione della dimensionalità che riduce i tipi di dati complessi in vettori a bassa dimensionalità. Trova punti dati che presentano somiglianze e li comprime in vettori di integrazione che riflettono i dati originali. Sebbene la PCA consenta ai modelli di elaborare i dati grezzi in modo più efficiente, potrebbe verificarsi una perdita di informazioni durante l'elaborazione.
Decomposizione ai valori singolari
La decomposizione ai valori singolari (SVD) è un modello di integrazione che trasforma una matrice nelle sue matrici singolari. Le matrici risultanti mantengono le informazioni originali e al contempo consentono ai modelli di comprendere meglio le relazioni semantiche dei dati che rappresentano. I data scientist utilizzano SVD per svolgere diverse attività di ML, tra cui la compressione delle immagini, la classificazione del testo e i suggerimenti.
Word2Vec
Word2Vec è un algoritmo di ML addestrato ad associare parole e rappresentarle nello spazio di integrazione. I data scientist alimentano il modello Word2Vec attraverso enormi set di dati testuali per permettere la comprensione del linguaggio naturale. Il modello trova somiglianze tra le parole considerando il loro contesto e le relazioni semantiche.
Esistono due varianti di Word2Vec: Continuous Bag of Words (CBOW) e Skip-gram. CBOW consente al modello di predire una parola dal contesto dato, mentre Skip-gram deduce il contesto da una parola data. Sebbene Word2Vec sia un'efficace tecnica di integrazione di parole, non è in grado di distinguere accuratamente le differenze contestuali della stessa parola utilizzata per implicare significati diversi.
BERT
BERT è un modello linguistico basato su trasformatori addestrato con enormi set di dati per comprendere i linguaggi come fanno gli esseri umani. Come Word2Vec, BERT è in grado di creare integrazioni di parole partendo dai dati di input con cui è stato addestrato. Inoltre, BERT è in grado di distinguere i significati contestuali delle parole quando vengono applicati a frasi diverse. Ad esempio, BERT crea diverse integrazioni per "partita", come in "Sono andato a vedere la partita" e "Sono partita stamattina".
Come vengono create le integrazioni?
Gli ingegneri utilizzano le reti neurali per creare integrazioni. Le reti neurali sono costituite da livelli neuronali nascosti che prendono decisioni complesse in modo iterativo. Durante la creazione di integrazioni, uno dei livelli nascosti impara a fattorizzare le funzionalità di input in vettori. Ciò si verifica prima dei livelli di elaborazione delle funzionalità. Questo processo è supervisionato e guidato da ingegneri attraverso i seguenti passaggi:
- Gli ingegneri alimentano la rete neurale con alcuni campioni vettoriali preparati manualmente.
- La rete neurale apprende dai modelli scoperti nel campione e utilizza le conoscenze per fare previsioni accurate a partire da dati invisibili.
- Talvolta, gli ingegneri potrebbero dover ottimizzare il modello per garantire che distribuisca le funzionalità di input nello spazio dimensionale appropriato.
- Nel tempo, le integrazioni funzionano in modo indipendente, consentendo ai modelli di ML di generare suggerimenti dalle rappresentazioni vettoriali.
- Gli ingegneri continuano a monitorare le prestazioni dell'integrazione e a perfezionare i nuovi dati.
In che modo AWS può aiutarti con i requisiti di integrazione?
Amazon Bedrock è un servizio completamente gestito che offre una scelta di modelli di fondazione (FM) ad alte prestazioni delle principali società di IA, insieme a un'ampia gamma di funzionalità per creare applicazioni di IA generativa. Amazon Nova è una nuova generazione di modelli di fondazione all'avanguardia che offrono intelligenza avanzata e rapporto tra prezzo e prestazioni leader nel settore. Sono modelli potenti e generici creati per supportare una molteplicità di casi d'uso. Utilizzali così come sono o personalizzali con i tuoi dati.
Titan Embeddings è un LLM che traduce il testo in una rappresentazione numerica. Il modello Titan Embeddings supporta il recupero del testo, la somiglianza semantica e il clustering. Il testo di input massimo è di 8000 token e la lunghezza massima del vettore di output è di 1536.
I team di machine learning possono anche utilizzare Amazon SageMaker per creare integrazioni. Amazon SageMaker è un hub in cui è possibile creare, addestrare e implementare modelli di ML in un ambiente sicuro e scalabile. Fornisce una tecnica di integrazione chiamata Object2Vec, con la quale gli ingegneri possono vettorializzare dati ad alta dimensione in uno spazio a bassa dimensione. È possibile utilizzare le integrazioni apprese per calcolare le relazioni tra oggetti per attività a valle come classificazioni e regressione.
Inizia subito a utilizzare le integrazioni su AWS creando un account.
Fasi successive su AWS
Ottieni accesso istantaneo al Piano gratuito di AWS.