AWS 기술 블로그

Neptune Stream을 통해 Neptune Database와 Neptune Analytics 간 데이터 동기화하기
Amazon Neptune 소개 Amazon Neptune은 AWS에서 제공하는 완전관리형 그래프 데이터베이스 서비스입니다. 이 서비스는 고도로 연결된 데이터셋을 효율적으로 저장하고 쿼리할 수 있도록 설계되었으며, 주로 소셜 네트워킹, 추천 엔진, 지식 그래프, 생명과학 연구 등의 분야에서 활용됩니다. Neptune은 업계 표준인 Property Graph와 RDF(Resource Description Framework)를 모두 지원하며, 각각 Apache TinkerPop Gremlin과 OpenCypher 그리고 SPARQL 쿼리 언어를 통해 데이터에 […]

MyDumper와 MyLoader를 사용하여 대용량 데이터베이스를 Amazon Aurora MySQL로 마이그레이션하기
이 글은 AWS Database Blog에 게시된 Migrate very large databases to Amazon Aurora MySQL using MyDumper and MyLoader by Maria Ehsan 을 한국어로 번역 및 편집하였습니다. Amazon Aurora는 클라우드를 위해 구축된 MySQL 및 PostgreSQL 호환 관계형 데이터베이스입니다. Aurora는 기존 엔터프라이즈 데이터베이스의 성능과 가용성을 오픈소스 데이터베이스의 단순성 및 비용 효율성과 결합했습니다. Aurora는 클러스터당 최대 15개의 저지연 […]

포스코홀딩스의 Managed Apache Flink를 활용한 효율적인 다수 CCTV 이벤트 처리 사례
포스코홀딩스는 한국의 대표적인 글로벌 철강 기업 포스코를 중심으로 이차전지 소재, 건설 등 다양한 사업 포트폴리오를 보유한 그룹 지주사입니다. 그룹 전체의 지속 가능한 성장을 추구하며, 특히 안전을 최우선 가치로 두고 있습니다. 사업장 내 안전사고 예방을 위해 끊임없이 노력하고 있습니다. 최근 AI 기술의 급격한 발전과 함께, 포스코홀딩스는 AI를 활용한 실시간 상황감지 시스템 구축에 많은 관심을 기울이고 있습니다. […]
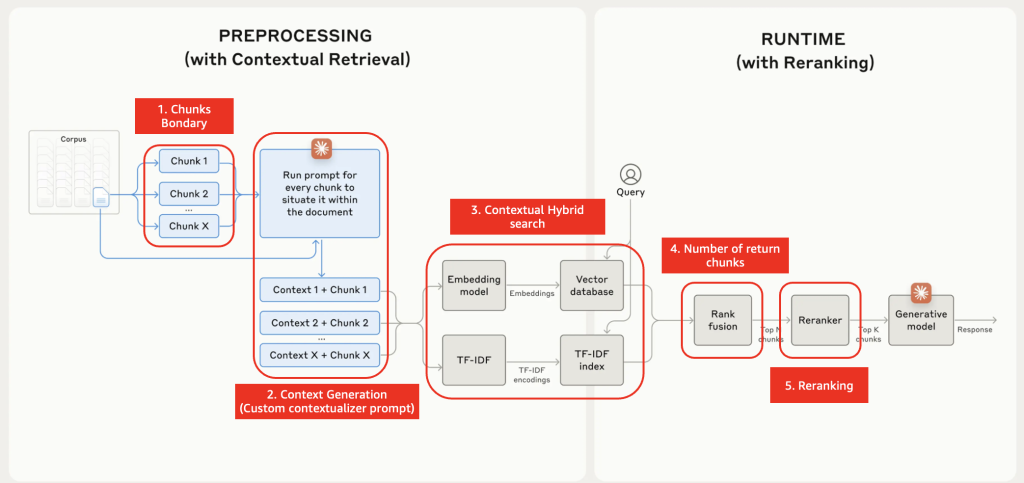
Amazon Bedrock기반에서 Contextual Retrieval 활용한 검색 성능 향상 및 실용적 구성 방안
개요 인공지능 기술의 발전과 함께 대규모 언어 모델(LLM)의 성능 향상을 위한 다양한 방법들이 연구되고 있습니다. 그 중에서도 Retrieval Augmented Generation (RAG)은 외부 지식을 활용하여 모델의 응답 능력을 크게 개선하는 주요 기술로 주목받고 있습니다. RAG는 사용자의 질문에 관련된 정보를 외부 데이터베이스에서 검색하고, 이를 프롬프트에 추가하여 더 정확하고 맥락에 맞는 응답을 생성하는 방식으로 작동합니다. 하지만 기존의 RAG […]

Amazon Bedrock과 AWS Config를 활용한 규제 요구사항 자동 매핑 도우미 – Part 1.
클라우드 보안 전문가로서 규제 준수는 항상 우리의 최우선 과제 중 하나입니다. 그러나 오늘날 클라우드 환경은 그 어느 때보다 복잡해지고 있으며, 규제 준수의 어려움도 함께 증가하고 있습니다. 금융, 의료, 공공 등 다양한 산업 분야에서 GDPR, HIPAA, PCI DSS, K-ISMS와 같은 다양한 규제 프레임워크를 동시에 준수해야 하는 상황이 일반화되었습니다. 이러한 규제 프레임워크들은 각각 수십-수백 개의 통제항목을 포함하고 […]
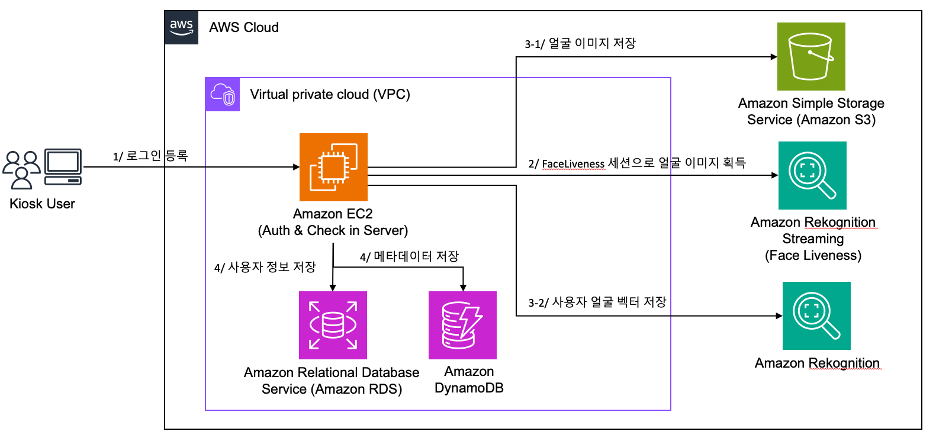
위커스의 Amazon Rekognition Face-Liveness를 활용한 얼굴 생체 인식 기반 무인 키오스크 구현
위커스(We Connect Space) 회사 소개 위커스(We Connect Space)는 공간 운영의 핵심 데이터를 연결하여, 회원 관리, 결제·수납, 예약, 좌석 관리 등 필수 기능을 하나의 AIoT SaaS 솔루션으로 제공합니다. 당사의 SaaS 기반 공간 운영 솔루션 ‘고스카 (GOSCA)’는 15개 이상의 업종에서 디지털 전환을 지원하고 있습니다. 스터디카페(무인·관리형), 키즈카페, 무인 탁구장 등 소상공인 공간 운영을 시작으로, 고등학교, 창업센터, 복지센터 등 […]

Amazon EBS 스냅샷으로부터 볼륨 생성을 위한 향상된 리소스 수준 권한 출시
이 글은 AWS Storage Blog에 게시된 Enhancing resource-level permission for creating an Amazon EBS volume from a snapshot by Emma Fu and Matt Luttrell를 한국어 번역 및 편집하였습니다. Amazon Elastic Block Store (Amazon EBS) 스냅샷은 애플리케이션 데이터 볼륨의 특정 시점 복사본을 생성하며, 이는 고객들이 새로운 볼륨을 생성할 때 기준점으로 활용할 수 있습니다. 이를 통해 다른 […]

굿리치의 온프레미스 DNS에서 Amazon Route 53 마이그레이션, 그 여정의 기록
굿리치는 국내 대표적인 법인보험대리점 (General Agency) 로 보험 판매와 인슈어테크 (보험+기술) 서비스를 제공하는 회사 입니다. 고객이 보험을 분석하고 상담받을 수 있는 서비스인 보험 관리 플랫폼, 종합 금융 컨설팅, 보험 비교 서비스 등 다양한 영역의 사업을 영위중이며 온프레미스 데이터센터에서 서비스 제공을 위한 다수의 IT 인프라를 보유하고 있었습니다. 최근 굿리치는 클라우드로의 전면적인 마이그레이션을 결정했습니다. 이는 IT 인프라의 […]

LinqAlpha 의 Amazon Bedrock과 Amazon OpenSearch 를 활용한 헤지펀드 투자사를 위한 Company Screener Agent
LinqAlpha 소개 LinqAlpha는 헤지펀드와 자산운용사를 위한 AI 기반 금융 리서치 솔루션을 제공하는 미국 기반 AI 스타트업으로, 방대한 시장 데이터를 신속하고 정확하게 분석하여 최적의 투자 결정을 지원합니다. 기관 투자자들은 글로벌 경제 지표와 기업 실적, 다양한 자산군의 가격 변동 등 복잡한 데이터를 실시간으로 처리해야 합니다. LinqAlpha는 최신 인공지능 기술 기반의 하이브리드 검색과 금융 특화 모델을 활용해 투자 […]

Amazon OpenSearch Service OR1 인스턴스 내부 구조 알아보기
이 글은 AWS Big Data Blog에 게시된 ‘Amazon OpenSearch Service Under the Hood’를 번역 및 개선했습니다. Amazon OpenSearch Service는 Optimized Instance(OR1)를 제공하고 있습니다. 이 새로운 제품군은 벤치마크 테스트에서 기존 메모리 최적화 인스턴스보다 가격 대비 성능이 최대 30% 향상되었습니다. 이는, OR1 인스턴스는 내부적으로 Amazon S3를 활용하기 때문이며 이러한 특징으로 OR1 인스턴스는 11 9s의 뛰어난 데이터 내구성을 […]