Amazon SageMaker Data Wrangler
기계 학습용 데이터를 준비하는 가장 빠르고 쉬운 방법 - 이제 SageMaker Canvas를 사용하세요
왜 SageMaker Data Wrangler를 사용해야 할까요?
Amazon SageMaker Data Wrangler는 테이블 형식, 이미지 및 텍스트 데이터의 데이터 준비 시간을 몇 주에서 몇 분으로 단축합니다. SageMaker Data Wrangler를 사용하면 자연어를 사용하는 시각적 인터페이스를 통해 데이터 준비 및 특성 엔지니어링을 간소화할 수 있습니다. 코드를 작성하지 않고도 SQL과 300개 이상의 내장 변환을 사용하여 데이터를 빠르게 선택하고 가져오고 변환할 수 있습니다. 직관적인 데이터 품질 보고서를 생성하여 데이터 유형 전반에서 이상 항목을 탐지하고 모델 성능을 추정합니다. 페타바이트 규모의 데이터를 처리할 수 있도록 확장합니다.
SageMaker Data Wrangler의 이점
작동 방식
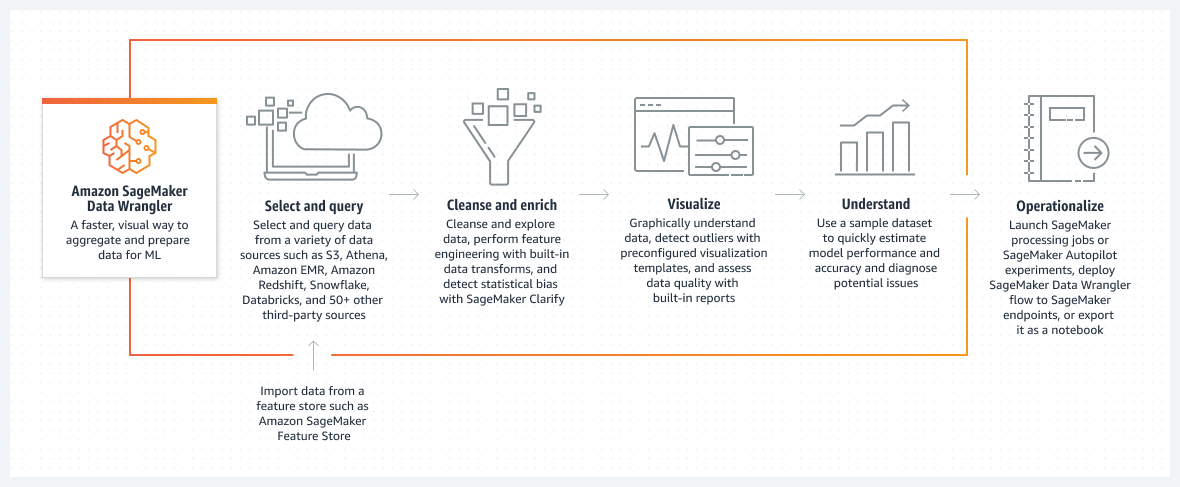
작동 방식

제목 1: Amazon SageMaker Data Wrangler
설명 텍스트: ML용 데이터를 시각적으로 집계하고 준비하는 빠른 방법
제목 2: 선택 및 쿼리
설명 텍스트: Amazon S3, Athena, Amazon EMR, Amazon Redshift, Snowflake, Databricks 및 50개 이상의 기타 서드 파티 소스를 포함한 다양한 데이터 소스에서 데이터를 선택하고 쿼리
하위 설명: Amazon SageMaker 특성 저장소와 같은 특성 저장소에서 데이터 가져오기
제목 3: 정리 및 보강
설명 텍스트: 데이터를 정리 및 탐색하고 기본 제공 데이터 변환을 사용하여 특성 추출을 수행한 후 SageMaker Clarify로 통계적 바이어스 검색
제목 4: 시각화
설명 텍스트: 데이터를 그래픽으로 파악하고 미리 구성된 시각화 템플릿을 사용하여 이상값을 감지한 후 기본 제공 보고서를 통해 데이터 품질 평가
제목 5: 이해
설명 텍스트: 샘플 데이터 세트를 사용하여 모델 성능 및 정확성을 빠르게 예측하고 잠재적 문제를 진단
제목 6: 운영화
설명 텍스트: SageMaker 처리 작업 또는 SageMaker Autopilot Experiments를 시작하거나 SageMaker Data Wrangler 흐름을 SageMaker 엔드포인트에 배포하거나 노트북으로 내보내기
신속한 데이터 액세스, 선택 및 쿼리
SageMaker Data Wrangler를 사용하면 S3, Athena, Redshift와 같은 Amazon 서비스와 50개 이상의 서드 파티 소스에서 테이블 형식, 텍스트 및 이미지 데이터에 빠르게 액세스할 수 있습니다. 시각적 쿼리 빌더로 데이터를 선택하거나, SQL 쿼리를 작성하거나, CSV 및 Parquet과 같은 다양한 형식으로 데이터를 직접 가져올 수 있습니다.

데이터 인사이트를 생성하고 데이터 품질을 확인
SageMaker Data Wrangler는 데이터 품질(예: 누락 값, 중복 행 및 데이터 유형)을 자동으로 확인하고 데이터의 이상(예: 이상값, 클래스 불균형 및 데이터 누수)을 감지하는 데 도움이 되는 데이터 품질 및 인사이트 보고서를 제공합니다. 데이터 품질을 효과적으로 확인한 후에는 도메인 지식을 빠르게 적용하여 ML 모델 훈련을 위한 데이터 세트를 처리할 수 있습니다.

시각화를 통해 데이터 이해
SageMaker Data Wrangler는 히스토그램, 산점도, 특성 중요도, 상관 관계와 같은 강력한 기본 제공 시각화 템플릿을 통해 데이터를 이해하는 데 도움이 됩니다. 데이터 유형 전반에서 이상 현상을 탐지하고 데이터 품질 개선을 위한 권장 사항을 제공하는 직관적인 데이터 품질 보고서를 통해 데이터 탐색을 가속화할 수 있습니다.

보다 효율적인 데이터 변환
SageMaker Data Wrangler는 300개 이상의 사전 구축된 PySpark 변환과 자연어 인터페이스를 제공하여 코딩 없이 테이블 형식, 시계열, 텍스트 및 이미지 데이터를 준비할 수 있습니다. 텍스트 벡터화, 날짜/시간 특성화, 인코딩, 데이터 밸런싱 또는 이미지 증강과 같은 일반적인 사용 사례를 다룹니다. PySpark, SQL 및 Pandas에서 사용자 지정 변환을 작성하거나 자연어 인터페이스를 사용하여 코드를 생성할 수도 있습니다. 코드 조각 라이브러리가 내장되어 사용자 지정 변환 작성이 간소화됩니다.

데이터의 예측 능력 이해
SageMaker Data Wrangler는 데이터의 예측력을 추정하기 위한 퀵 모델 분석을 제공합니다. 추정된 모델 정확도, 특성 중요도, 오차 행렬을 통해 모델을 훈련하기 전에 데이터 품질을 검증할 수 있습니다.

ML 데이터 준비 워크플로 자동화 및 배포
SageMaker Data Wrangler를 사용하면 PySpark를 코딩하거나 클러스터를 가동하지 않고도 페타바이트 규모의 데이터를 준비할 수 있도록 확장할 수 있습니다. UI에서 바로 처리 작업을 시작하거나 데이터를 SageMaker 특성 저장소로 내보내거나 SageMaker Pipelines와 통합하여 데이터 준비를 ML 워크플로에 통합할 수 있습니다. 데이터 흐름을 Jupyter Notebook 또는 Python 스크립트로 내보내 데이터 준비 단계를 프로그래밍 방식으로 복제할 수도 있습니다.

고객
"INVISTA에서는 변환을 기반으로, 전 세계 고객에게 유용한 기술과 제품을 개발하고자 노력하고 있습니다. 우리는 ML이 고객 경험을 개선하는 방법임을 목격하고 있습니다. 하지만 수억 개의 행에 걸쳐 있는 데이터 세트를 사용하기 위해서는 데이터를 준비하고 ML 모델을 규모에 맞게 개발, 배포, 관리하도록 도와주는 솔루션이 필요했습니다. 이제 Amazon SageMaker Data Wrangler를 사용하여 대화식으로 데이터를 효과적으로 선택, 정리, 탐색 및 이해할 수 있으므로 데이터 과학 팀이 수억 개의 행에 걸쳐 있는 데이터 세트로 손쉽게 확장할 수 있는 특성 추출 파이프라인을 생성할 수 있게 되었습니다. Amazon SageMaker Data Wrangler로 ML 워크플로를 더 빠르게 운영할 수 있습니다."
Caleb Wilkinson, INVISTA, 전 Lead Data Scientist
“ML을 사용하면서, 3M은 사포와 같이 검증된 제품을 개발하고자 노력하고 있으며, 의료 분야를 포함해 기타 여러 분야에서 혁신을 주도하고 있습니다. ML을 3M의 더 많은 영역으로 확장하려는 계획을 세우면서 데이터와 모델의 양이 매년 2배씩 매우 빠르게 증가한다는 사실을 확인했습니다. 새로운 SageMaker 피처는 확장을 지원해줄 수 있다는 점에서 매우 반가울 소식이 아닐 수 없습니다. Amazon SageMaker Data Wrangler를 사용하면 모델 훈련을 위해 더욱 간편하게 데이터를 준비할 수 있고, Amazon SageMaker 특성 저장소를 통해 동일한 모델 피처를 반복해서 만들지 않아도 됩니다. 마지막으로, Amazon SageMaker Pipelines는 포괄적인 워크플로 단계로 데이터 준비, 모델 구축 및 모델 배포를 자동화해주므로, 모델의 시장 출시 기간을 단축할 수 있습니다. 저희 3M에서는 이러한 보다 빠른 속도의 과학을 활용할 수 있기를 기대하고 있습니다."
David Frazee, 3M Corporate Systems Research Lab, 전 Technical Director
"Amazon SageMaker Data Wrangler를 통해 새로운 제품을 시장에 출시하는 데 필요한 ML 데이터 준비 프로세스를 가속화해주는 다양한 변환 도구 모음을 사용하여 데이터 준비 요구 사항을 성공적으로 해결할 수 있습니다. 그리고 배포된 모델을 빠르게 확장하면서 고객 요구 사항을 충족시키는 측정 가능하고 지속 가능한 결과를 수개월이 아니라, 불과 며칠 안에 지원할 수 있으므로, 고객도 혜택을 누릴 수 있습니다."
Frank Farrall, Deloitte Principal, AI Ecosystems and Platforms Leader
"저희 엔지니어링 팀은 AWS 프리미어 컨설팅 파트너로서 AWS와 긴밀하게 협력하면서 고객이 운영 효율성을 지속적으로 개선할 수 있는 혁신적인 솔루션을 구축하고 있습니다. ML은 혁신적인 저희 솔루션의 핵심이지만, 데이터 준비 워크플로에는 정교한 데이터 준비 기법이 포함되므로, 프로덕션 환경에서 운영되기까지 상당한 시간이 소요됩니다. Amazon SageMaker Data Wrangler를 사용하면 데이터 선택, 정리, 탐색, 시각화 등 데이터 준비 워크플로의 각 단계를 수행할 수 있어 데이터 준비 프로세스를 가속화하고 ML을 위한 데이터를 손쉽게 준비할 수 있습니다. Amazon SageMaker Data Wrangler를 사용하면 ML을 위한 데이터를 보다 빠르게 준비할 수 있습니다."
Shigekazu Ohmoto, NRI Japan Senior Corporate Managing Director
"인구 건강 관리 시장에서 당사의 입지가 더 많은 의료 납부자, 공급자, 보험약제 관리기업 등으로 확대됨에 따라 청구 데이터, 등록 데이터 및 약제 데이터를 비롯해 ML 모델을 제공하는 데이터 소스에 대한 엔드 투 엔드 프로세스를 자동화하는 솔루션이 필요했습니다. 이제 Amazon SageMaker Data Wrangler를 통해 검증 및 재사용이 더 쉬운 워크플로 세트를 사용하여 ML을 위한 데이터를 집계하고 준비하는 데 소요되는 시간을 단축할 수 있습니다. 이를 통해 모델의 제공 시간과 품질이 크게 향상되고 데이터 과학자의 효율성이 향상되었으며 데이터 준비 시간이 거의 50% 단축되었습니다. 또한 SageMaker Data Wrangler는 약국, 진단 코드, 응급실 방문, 입원은 물론 인구 통계 및 기타 사회적 결정 요인을 포함한 수천 가지 기능을 갖춘 데이터 마트를 구축할 수 있기 때문에 여러 ML 반복과 상당한 GPU 시간을 절약하여 고객의 전체 엔드 투 엔드 프로세스를 가속화하는 데 도움이 되었습니다. SageMaker Data Wrangler를 사용하면 교육용 데이터 세트를 구축하는 데 있어서 탁월한 효율성으로 데이터를 변환하고, ML 모델을 실행하기 전에 데이터 세트에 대한 데이터 인사이트를 생성하고, 대규모 추론/예측을 위해 실제 데이터를 준비할 수 있습니다.”
Lucas Merrow, Equilibrium Point IoT CEO