



Qual é a diferença entre machine learning supervisionado e não supervisionado?
Machine learning (ML) supervisionado e não supervisionado são duas categorias de algoritmos de ML. Os algoritmos de ML processam grandes quantidades de dados históricos para identificar padrões de dados por meio de inferência.
Os algoritmos do aprendizado supervisionado treinam com base em dados de amostra que especificam a entrada e a saída do algoritmo. Por exemplo, os dados podem ser imagens de números manuscritos que são anotados para indicar quais números representam. Com dados rotulados suficientes, o sistema de aprendizado supervisionado acabaria reconhecendo os clusters de pixels e formas associados a cada número escrito à mão.
Os algoritmos de aprendizado não supervisionado são treinados em dados não rotulados. Eles verificam dados novos e estabelecem conexões significativas entre a entrada desconhecida e as saídas predeterminadas. Por exemplo, algoritmos de aprendizado não supervisionado podem agrupar artigos de diferentes sites de notícias em categorias comuns, como esportes e crimes.
Técnicas: aprendizado supervisionado vs. não supervisionado
Em machine learning, ensinamos um computador a fazer previsões ou inferências. Primeiro, usamos um algoritmo e dados de exemplo para treinar um modelo. Em seguida, integramos o modelo à aplicação para gerar inferências em tempo real e em escala. O aprendizado supervisionado e o não supervisionado são duas categorias distintas de algoritmos.
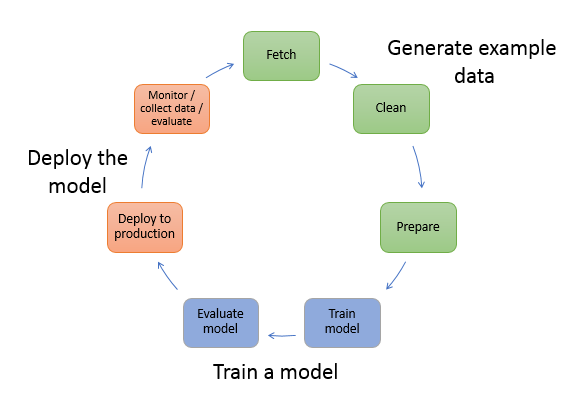
Aprendizado supervisionado
No aprendizado supervisionado, treinamos o modelo com um conjunto de dados de entrada e um conjunto correspondente de dados de saída rotulados emparelhados. A rotulagem geralmente é feita manualmente. Veja a seguir alguns tipos de técnicas de machine learning supervisionado.
Regressão logística
A regressão logística prevê uma saída categórica com base em uma ou mais entradas. A classificação binária é quando a saída se encaixa em uma de duas categorias, como sim ou não e aprovação ou reprovação. A classificação de várias classes é quando a saída se encaixa em mais de duas categorias, como gato, cachorro ou coelho. Um exemplo de regressão logística é prever se um aluno será aprovado ou reprovado em um módulo com base no número de logins no material didático.
Leia sobre regressão logística »
Regressão linear
A regressão linear refere-se a modelos de aprendizado supervisionado que, com base em uma ou mais entradas, preveem o valor de uma escala contínua. Um exemplo de regressão linear é a previsão do preço de uma casa. É possível prever o preço de uma casa com base na localização, na idade e na quantidade de cômodos, depois de treinar um modelo em um conjunto de dados históricos de treinamento de vendas com essas variáveis.
Árvore de decisão
A técnica de aprendizado de machine learning por árvore de decisão usa algumas entradas e aplica uma estrutura if-else para prever um resultado. Um exemplo de problema de árvore de decisão é a previsão da rotatividade de clientes. Por exemplo, se o cliente não acessar uma aplicação depois de se inscrever, o modelo poderá prever a rotatividade. Ou se o cliente acessar a aplicação em vários dispositivos e o tempo médio da sessão estiver acima de determinado limite, o modelo poderá prever a retenção.
Rede neural
A solução de rede neural é uma técnica de aprendizado supervisionado mais complexa. Para produzir determinado resultado, ele usa algumas entradas e executa uma ou mais camadas de transformação matemática com base no ajuste das ponderações dos dados. Um exemplo de técnica de rede neural é a previsão de um dígito com base em uma imagem manuscrita.
Aprendizado não supervisionado
O machine learning não supervisionado é aquele em que fornecemos dados de entrada ao algoritmo sem nenhum dado de saída rotulado. Então, sozinho, o algoritmo identifica padrões e relacionamentos nos dados e entre eles. Veja a seguir alguns tipos de técnicas de aprendizado não supervisionado.
Agrupamento em clusters
A técnica de aprendizado não supervisionado de agrupamento em clusters agrupa determinadas entradas de dados, para que possam ser categorizadas como um todo. Existem vários tipos de algoritmos de agrupamento em clusters, dependendo dos dados de entrada. Um exemplo de clustering é a identificação de diferentes tipos de tráfego de rede para prever possíveis incidentes de segurança.
Aprendizado de regras de associação
As técnicas de aprendizado de regras de associação revelam relações baseadas em regras entre entradas em um conjunto de dados. Por exemplo, o algoritmo Apriori conduz uma análise da cesta de mercado para identificar regras como café e leite frequentemente comprados juntos.
Densidade de probabilidade
As técnicas de densidade de probabilidade no aprendizado não supervisionado preveem a probabilidade ou a possibilidade de o valor de uma saída estar dentro da faixa do que é considerado normal para uma entrada. Por exemplo, um medidor em uma sala de servidores normalmente registra uma temperatura entre um determinado intervalo de graus. Porém, se ele medir repentinamente um número baixo com base na distribuição de probabilidade, isso poderá indicar defeito no equipamento.
Redução de dimensionalidade
A redução de dimensionalidade é uma técnica de aprendizado não supervisionado que reduz o número de atributos em um conjunto de dados. Geralmente, é usada para pré-processar dados para outras funções de machine learning e reduzir a complexidade e as despesas gerais. Por exemplo, ela pode desfocar ou cortar atributos de fundo em uma aplicação de reconhecimento de imagem.
Quando usar: aprendizado supervisionado vs. não supervisionado
Você pode usar técnicas de aprendizado supervisionado para solucionar problemas com resultados conhecidos e que tenham dados rotulados disponíveis. Os exemplos incluem classificação de spam por e-mail, reconhecimento de imagem e previsões de preços de ações com base em dados históricos conhecidos.
Você pode usar o aprendizado não supervisionado para cenários em que os dados não estejam rotulados e o objetivo seja descobrir padrões, agrupar instâncias semelhantes ou detectar anomalias. Também é possível usá-lo para tarefas exploratórias em que os dados rotulados estejam ausentes. Os exemplos incluem organizar grandes arquivos de dados, criar sistemas de recomendação e agrupar clientes com base nos comportamentos de compra.
É possível usar o aprendizado supervisionado e não supervisionado juntos?
O aprendizado semissupervisionado é aquele em que aplicamos técnicas de aprendizado supervisionado e não supervisionado a um problema comum. É outra categoria de machine learning em si.
Podemos aplicar o aprendizado semissupervisionado quando é difícil obter rótulos para um conjunto de dados. Você pode ter um volume menor de dados rotulados, mas uma quantidade significativa de dados não rotulados. Em comparação com o uso exclusivo do conjunto de dados rotulado, você teria maior precisão e eficiência se combinasse técnicas de aprendizado supervisionado e não supervisionado.

Estes são alguns exemplos de aplicações de aprendizado semissupervisionado.
Identificação de fraudes
Em um grande conjunto de dados transacionais, há um subconjunto de dados rotulados em que especialistas confirmaram transações fraudulentas. Para obter um resultado mais preciso, a solução de machine learning treinaria primeiro os dados não rotulados e depois os dados rotulados.
Análise de sentimento
Ao considerar a amplitude das interações com os clientes baseadas em texto de uma organização, categorizar ou rotular o sentimento em todos os canais pode não apresentar um bom custo-benefício. A organização pode treinar primeiro um modelo na maior parte não rotulada dos dados e depois em uma amostra que tenha sido rotulada. Isso proporcionaria à organização um maior grau de confiança no sentimento do cliente em toda a empresa.
Classificação de documentos
Ao aplicar categorias a uma grande base de documentos, pode haver documentos em excesso para serem rotulados fisicamente. Por exemplo, podem ser inúmeros relatórios, transcrições ou especificações. Para começar, o treinamento sobre os dados não rotulados ajuda a identificar documentos semelhantes para rotulagem.
Resumo das diferenças: aprendizado supervisionado vs. não supervisionado
| Aprendizado supervisionado |
Aprendizado sem supervisão |
|
| O que é isso? |
Você treina o modelo com um conjunto de dados de entrada e um conjunto correspondente de dados de saída rotulados emparelhados. |
Você treina o modelo para descobrir padrões ocultos em dados não rotulados. |
| Técnicas |
Regressão logística, regressão linear, árvore de decisão e rede neural. |
Agrupamento em clusters, aprendizado de regras de associação, densidade de probabilidade e redução de dimensionalidade. |
| Objetivo |
Prever uma saída com base em entradas conhecidas. |
Identificar informações valiosas de relacionamento entre os pontos de dados de entrada. Isso pode então ser aplicado a uma nova entrada para extrair insights semelhantes. |
| Abordagem |
Minimizar o erro entre as saídas previstas e os rótulos verdadeiros. |
Encontrar padrões, semelhanças ou anomalias nos dados. |
Como a AWS pode ajudar com o aprendizado supervisionado e não supervisionado?
A Amazon Web Services (AWS) oferece uma ampla variedade de ofertas que ajudam você com machine learning (ML) supervisionado, não supervisionado e semissupervisionado. É possível criar, executar e integrar soluções de qualquer tamanho, complexidade ou caso de uso.
O Amazon SageMaker é uma plataforma completa para criar suas soluções de ML do zero. O SageMaker tem um conjunto completo de modelos predefinidos de aprendizado supervisionado e não supervisionado, recursos de armazenamento e computação e um ambiente totalmente gerenciado.
Por exemplo, estes são os atributos do SageMaker que você pode usar em seu trabalho:
- Use o Amazon SageMaker Autopilot para explorar automaticamente diferentes soluções e encontrar o melhor modelo para determinado conjunto de dados.
- Use o Amazon SageMaker Data Wrangler para selecionar dados, entender insights de dados e transformar dados para prepará-los para ML.
- Use o Amazon SageMaker Experiments para analisar e comparar iterações de treinamento de ML para escolher o modelo com melhor performance.
- Use o Amazon SageMaker Clarify para detectar e avaliar possíveis vieses. Dessa forma, os desenvolvedores de ML podem lidar com possíveis tendências e explicar as previsões do modelo.
Comece a usar machine learning supervisionado e não supervisionado na AWS criando uma conta hoje mesmo.
Próximas etapas com a AWS
Saiba como começar a usar machine learning supervisionado na AWS
Saiba como começar a usar o machine learning não supervisionado na AWS